

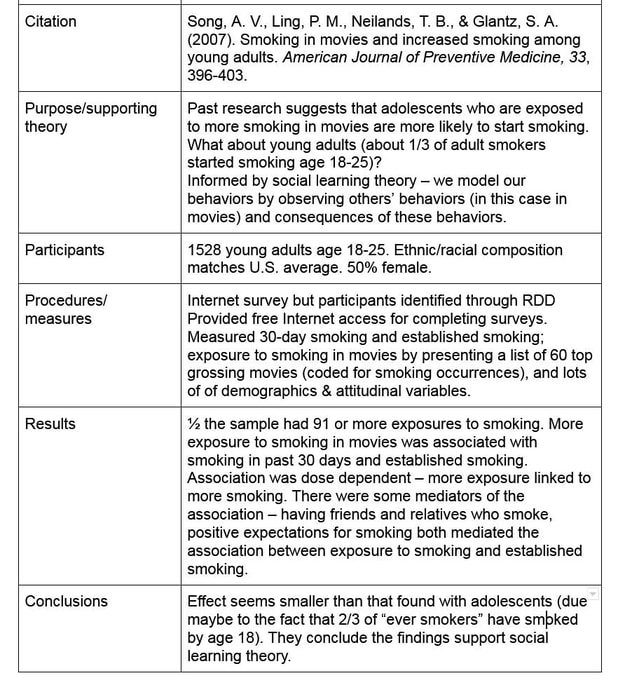
I am a huge fabric poster convert, and my goal is to convince everyone that their lives will be better if they use fabric posters. I do not have any investments in fabric poster companies, nor do I have affiliate links – I just think you will be happier if you too convert to fabric posters. Here are, in my opinion, the benefits of fabric posters:
- Goodbye poster tubes. No one enjoys carrying a poster tube through the airport, right? Or squeezing it into the overhead compartment? Or worrying that you will forget it on the plane? The only thing I will miss about poster tubes is easily being able to identify in the airport and at baggage claim who else is going to the same conference.
- Fold it and go. Perhaps related to the prior point, you can literally take a fabric poster, fold it, and put it in your carryon. I mean, you could put it in your checked bag too, but if they lose your checked bag, they lose your poster.
- Don’t worry about bending it. There is just no worry in your office or in the hotel room or anywhere else that someone will accidentally step on your poster and bend it. It can’t really get hurt.
- Iron if needed. If you really beat it up somehow, or you want zero creases, almost every hotel has an iron, and you can iron it.
- Reusable. It is much easier to save and reuse a fabric poster, if, for instance, you present it at your university after presenting it at your national conference.
- Cost. Hardest for me to believe was that fabric posters do not cost more than paper posters. The last poster – regular size – I ordered cost $16.20. Yes, I paid extra for expedited shipping, but that’s on me for submitting it last minute.
- Conversation starter. If most people are still using paper at the next conference you attend, lots of people will want to touch and ooh and aah over your fabric poster, and find out how you made it and how much it cost. Trust me.

So, I convinced you, and now YOU want to make your own fabric poster. But how? The website I have used is Spoonflower, recommended to me by Rose Wesche. Thanks to Mackenzie Wink for figuring out the details of how to use it and helping it get set up in our department. So most of this information comes from them.
1. Create a login
2. Click upload- you will upload a JPEG image of the poster
**PLEASE NOTE: THE POSTER MUST BE UPLOADED IN THE CORRECT FORMAT. It must be a JPEG not a PowerPoint or pdf. This link explains how to convert it.
3. If you have to come back to the account before being able to checkout with the order, the poster will be in your 'Design Library'
4. Ensure that settings are correct-
a. Centered (the default is a repeated design meaning multiple posters would print repeatedly on the poster like a fabric pattern)
b. 48X36
c. Performance Pique fabric
d. 1 yard
5. Make sure that the poster looks exactly how you want it in the preview window (make sure you can see the whole thing, etc.). This preview will be exactly how it prints.
6. checkout
It’s actually quite straightforward. And I bet once you try it, you will be converted for life. Until we all go to digital interactive posters.
1. Create a login
2. Click upload- you will upload a JPEG image of the poster
**PLEASE NOTE: THE POSTER MUST BE UPLOADED IN THE CORRECT FORMAT. It must be a JPEG not a PowerPoint or pdf. This link explains how to convert it.
3. If you have to come back to the account before being able to checkout with the order, the poster will be in your 'Design Library'
4. Ensure that settings are correct-
a. Centered (the default is a repeated design meaning multiple posters would print repeatedly on the poster like a fabric pattern)
b. 48X36
c. Performance Pique fabric
d. 1 yard
5. Make sure that the poster looks exactly how you want it in the preview window (make sure you can see the whole thing, etc.). This preview will be exactly how it prints.
6. checkout
It’s actually quite straightforward. And I bet once you try it, you will be converted for life. Until we all go to digital interactive posters.

“Where I convert you to fabric posters first appeared on Eva Lefkowitz’s blog on June 18, 2019.”
 RSS Feed
RSS Feed
